
前言
在处理PDF文件时,尤其是那些包含图片或扫描件内容的PDF文档,提取文字内容常常是一个令人头疼的问题。传统的文字提取工具往往无法准确识别图片中的文字,导致提取结果不准确或出现乱码。今天,我要向大家介绍一款名为“PDF的图片文字识别工具”的软件,它能够高效、准确地从PDF文档中提取文字内容,支持多种功能,满足用户在不同场景下的需求。
软件介绍
PDF的图片文字识别工具是一款专为PDF文档设计的文字提取软件,能够识别并提取PDF文件中的文字内容,包括图片和扫描件中的文字。该工具支持单文件选择和多文件批量选择,用户可以根据自己的需求选择合适的操作方式。软件还提供了文字预处理和结果后处理功能,确保提取的文字内容准确无误。
采用了先进的光学字符识别(OCR)技术,能够高效、准确地识别PDF文档中的文字内容。无论是清晰的打印文字还是模糊的扫描件文字,该工具都能快速提取并转换为可编辑的文字格式。这对于需要从PDF文档中提取大量文字的用户来说非常实用,能够大大节省时间和精力。
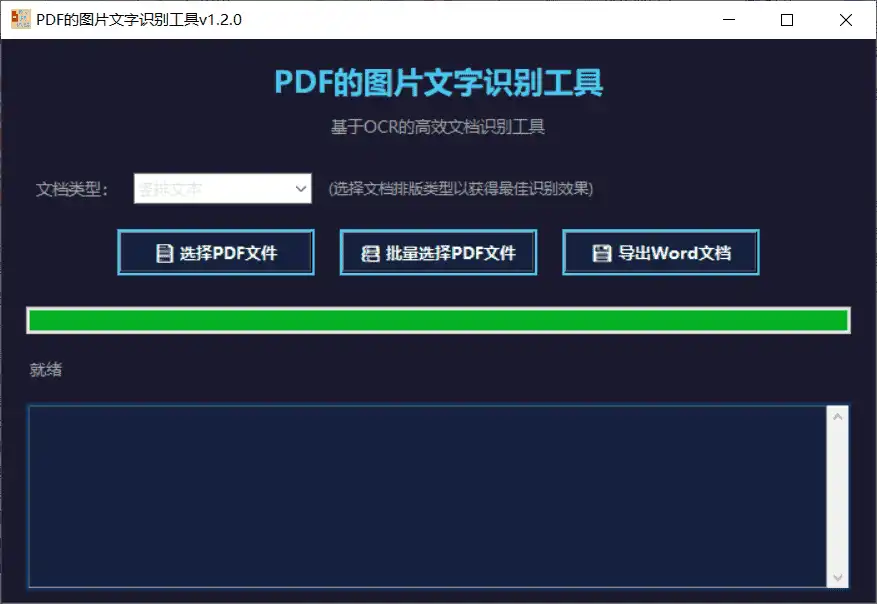

该工具支持单文件选择和多文件批量选择,用户可以根据自己的需求选择合适的操作方式。对于需要处理多个PDF文件的用户,批量选择功能可以一次性处理多个文件,极大地提高了工作效率。用户只需选择需要处理的文件,点击“开始识别”按钮,软件将自动完成文字提取并生成结果。
软件以其高效的文字识别能力、支持单文件和多文件批量选择、文字预处理和结果后处理功能、支持竖排文字识别、支持导出为Word文档、绿色免安装以及便利的交互设计,为用户提供了便捷的PDF文档文字提取解决方案。